 |
max payne 3 |
| I am currently an infrastructure engineer at deviantART, working on multiple projects mostly involving machine learning, such as improving More Like This |
 |
max payne 3 |
| I was an artificial intelligence engineer for the critically acclaimed game Max Payne 3. |
 |
affordance-based concepts |
| In my thesis work, I treated perceived affordances as a basis for understanding situated language. Using a probabilistic hierarchical plan recognizer, I cast language as a filtering process on the predictions this recognizer makes or has made. Thus, a word like "door" means all the ways you could interact with doors in the past or present - you could open them, break them, unlock them or walk through them. As a language parser finds structure in an utterance, it also filters the set of relevant affordances, forming what I call an Affordance-Based Concept. In practise, this works quite well for understanding highly situated-dependent speech in puzzle-solving games. You can read all about this work in my thesis, and get more information about related work as well as some videos at the Cogmac Games Page. There are more (and shorter) papers about this work forthcoming shortly. |
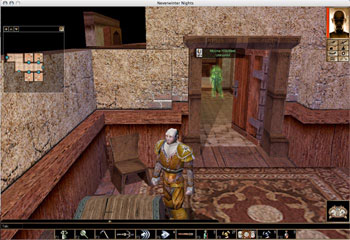 |
situated speech |
Speech
and language do not occur in a vacuum - much of the meaning of
an utterance comes from its context, including when and where it was
uttered, what the person saying it was doing at the time, who was there
to listen to it, and why the speaker decided to speak in the first
place. I am now applying some of the insights gained from my bishop
project to a broader context - one that includes multiple speakers who
can move around, acquire and use items and solve problems together. To
make the sensing and context tracking problems trackable, I am using
off-the-shelf online role playing games as rich yet controllable
environments. You can find my plans detailed in my thesis proposal, a paper from a games conference as well as a paper that won an award at a multimodal interface conference.
|
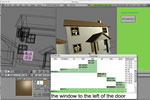 |
bishop|blender |
| All
3D modeling applications face the problem of letting their users
interact with a 2D projection of a 3D scene. Rather than the common
solutions that include multiple views, and selective display and
editing of the scene, I here employed my previous work in understanding
spatially grounded natural language to allow for speech-based selection
and manipulation of objects in the 3D scene. This is an application of
my bishop
project to the open source 3D modeling application blender.
Here is a video
of bishop|blender in action. I demoed this at NAACL 2004, with an
accompanying short
description. |
 |
bishop |
| The
bishop
project started with a study of how human beings describe
hard-to-distinguish objects in cluttered scenes to each other. I
analyzed the descriptive strategies (combinations of linguistic and
visual features) people used. Using a catalogue of these strategies I
wrote a parser that computes similar visual and spatial features while
parsing spoken utterances and can perform what I call grounded semantic
composition of these features to determine the speaker's intended
referent. There are several publications about this project including
an article
in the Journal of Artificial Intelligence Research and a shorter paper
describing an application to multimodal interfaces from the
International Conference on Multimodal Intefaces. Also see the bishop|blender
project above. |
 |
newt |
| Newt
is a small pan-and-tilt robot with a camera as an eye and a laser
pointer as nose and pointing device. Newt looks at objects on the table
and learns object names, colours and some spatial relations by a
show-and-tell procedure. I wrote a grammar learning algorithm for this
project that consisted of a number of processes that self-configured to
represent a grammar and visual groundings for lexical and grammatical
items. We published a paper
describing this work at the International Conference on Spoken Language
Processing. You can also watch a video
of this project. |
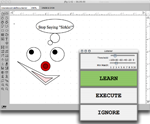 |
jfig |
| This
project is an application of a simple version of Deb's word learning
algorithm to jfig,
a 2D drawing application. As the artist uses tools in the application,
he or she can speak names for the tools. After only a few examples, our
learning algorithm reacts to speech commands thus trained by selecting
tools for the user. The application quickly learns a small set of
commands without a separate training phase and robustly ignores any
speech without learned tool associations. Using work I did for my
Master's thesis, all of this is possible without modifying (or even
having the source code) for the drawing application so augmented. We
published a short paper
on this in the International Conference on Multimodal Interaces. Here
is a video
of this project in action. |
 |
dobie |
| During
a GROP (Graduate Research Opportunities Program) with Bruce Blumberg's
Synthetic Characters group, I applied my Master's thesis work on
learning Markov models by observing another agent to their synthetic
dog, Dobie. In a computational version of training dogs by backwards
chaining, this let a human teacher train Dobie to perform sequences of
actions with relatively few incremental examples while mainting all of
Dobie's other learning behaviours. You can read a conference paper about this. |
 |
cyko |
| Taking
Rod Brooks' class, Ben Yoder and I got interested in the question of
whether one could evaluate the creatures produced by genetic algorithm
in the real world. Thus, the CYKOs (Self Improving Computational
kOmmunicators) started evolving. They are creatures with a dictionary
of phoneme strings that they pronounce through a speaker. They then
listen to themselves speak through a microphone, and we measure how
many of their own utterances they correctly recognize, and use that as
a fitness function. We investigated whether they do learn to listen to
themselves (they do), what effects different kinds of noises have on
their evolution and whether we can make sense of whatthey evolve into.
You can read our report
here. |
 |
ubc |
| Before
coming to the MIT Media Laboratory I completed undergraduate and
Master's degrees at the University of British Columbia, Canada. For my
Master's thesis, I developed algorithm to perform online and offline
estimation of Markov models by observing people use applications
without knowing what they are doing or even the applications' purposes.
This lead to a good algorithm to predict what users are going to do
next given their history (AAAI
paper)
and a related algorithm to build an explicit model of what the user has
been doing with the application (UAI
paper).
In my thesis,
I cover both of these in detail and extend them to perform general HMM
structure derivation from observations. Both the algorithms and the
framework I used to examine unmodified applications appear in my later
research on training
synthetic dogs to perform sequences of actions
and
learning speech commands for unmodified applications,
respecively. |
{kind=link}